java和c++之间有一堵由内存动态分配和垃圾收集技术所围成的高墙,墙外的人想进去,墙里的人想出来。
为什么需要GC
如今的内存动态分配与内存回收技术已经想当成熟,一切看起来进入了“自动化”的时代,那我们为什么还需要了解垃圾收集和内存分配呢?理由主要如下:
- 排查各种内存溢出,内存泄漏的问题
- 使系统达到更高的并发
上一篇文章提到的java运行时区域的各个部分,其中程序计数器,JVM栈,本地方法栈这3个区域随线程而生,随线程而灭,栈中的frame随着方法的进出执行入栈和出栈的操作。这几个区域内存分配和回收具有确定性,当方法和线程结束时,内存自然就回收了。
但是java堆和方法区则具有明显的不确定性:一个接口的多个实现类的内存可能会不一样,一个方法执行的不同分支所需的内存也可能不一样,只有处于运行期间,才能知道程序究竟会创建哪些对象,创建多少对象,这个部分的内存分配和回收是动态的。垃圾收集器关注的正是这部分内存的管理问题。
对象的存活问题
在堆中存放这几乎所有的对象实例,垃圾收集器在对heap进行回收前,首先要确定这些对象中哪些“存活”,哪些已经“死去”。
- 引用计数算法:在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值加1;当引用失效时,计数器值减1;任何时刻计数器为0的对象是不可能再被使用的。(java主流的VM中没有使用这种方式来管理内存,因为它很难解决对象之间相互循环引用的问题)
- 可达性分析算法:当前主流的商用程序语言的内存管理子系统,都是通过可达性分析(reachability analysis)算法来判断对象是否存活的。基本思路:通过一系列称为”GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”,如果某个对象到GC Roots间没有任何引用链相连,即不可达时,则证明此对象是不可能再被使用的。
上面两种方法都提到了引用的概念,JDK1.2之前的定义:如果reference类型的数据中存储的数值代表的是另一块内存的起始地址,就称该reference数据是代表某块内存、某个对象的引用。在JDK1.2之后,Java对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用和虚引用,这4种引用强度依次减弱。
GC算法
当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集(Generational Collection)”的理论进行设计,它建立在2个分代假说之上:
- 弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的
- 强分代假说(Strong Generational Hypothesis):熬过越多次的GC过程的对象就越难消亡
把分代收集理论放到现在商用的java虚拟机中,设计者一般至少把java堆分为新生代(Young Generation)和老年代(Old Generation)。在新生代中,每一次垃圾收集都发现大量的对象死去,而每次回收后存活的少量对象,将会逐步放到老年代中存放。但是对象之间会存在跨代引用:如果新生代的对象被老年代引用,为了找出该区域中的存活对象,不得不在固定的GC roots之外,额外遍历整个老年代所有对象来确保可达性分析结果的正确性。但这无疑会为内存回收带来很大的性能负担。为了解决这个问题,就需要对分代收集理论添加第三条经验法则:
- 跨代引用假说(Intergenerational reference hypothesis):跨代引用相对于同代引用来说仅占极少数
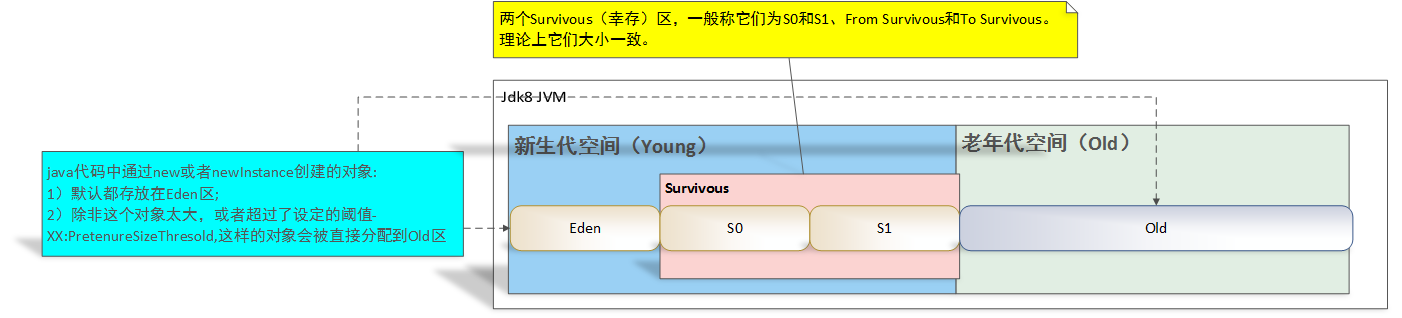
以上的是内存空间的分类:总体分为新生代和老年代两类,新生代又被分为两个区域(Eden,Survivor(to/form))
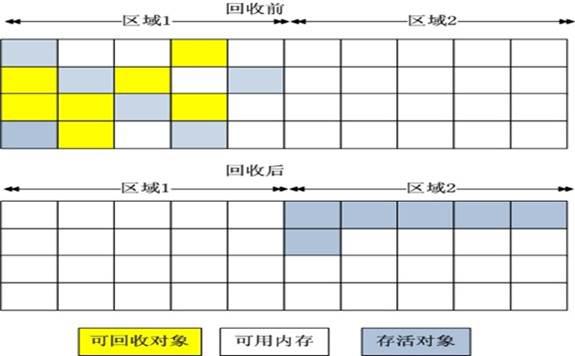
标记-清除
标记-清除的算法最简单,主要是标记出来需要回收的对象,然后把这些对象在内存的信息清除,但是会带来大量的内存碎片。
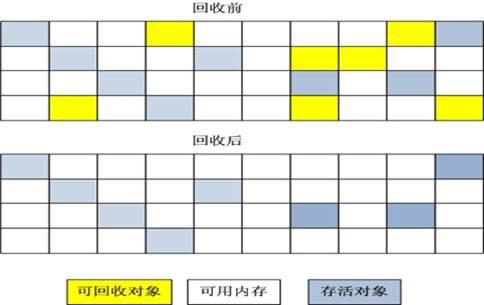
标记-压缩
有的时候也叫标记-清除-压缩,这个算法是在标记-清除的算法基础之上进行剪切操作,将存活对象压缩在一起,减小内存碎片。由于压缩需要时间,会对GC收集的时间有影响。
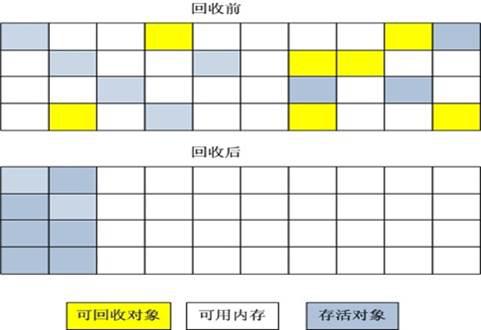
标记-复制
这个算法是把内存分配为两个空间,一个空间(A)用来负责装载正常的对象信息,另一个内存空间(B)用来GC。每一次把空间A存活的对象全部复制到空间B里面,再一次性把A删除。这个算法需要内存较大,内存利用率较低,适用于短期生存的对象。