
什么是集成学习
集成学习归属于机器学习,是一种训练思路,并不是某种具体的算法或者方法。集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型。集成学习的潜在思想是即使某一个弱分类器得到了错误的分类,其他的分类器也可以将其纠正回来。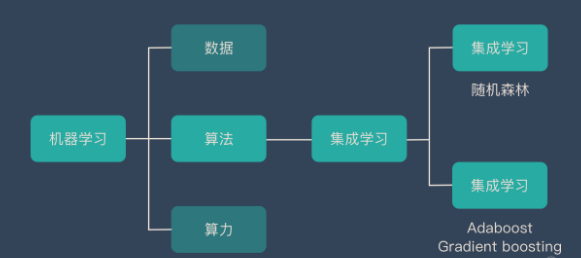
集成学习在各个数据规模的数据集上都有很好的表现:
- 数据集大:划分成多个小数据集,学习多个模型进行组合
- 数据集小:利用bootstrap方法进行抽样,得到多个数据集,分别训练多个模型进行组合
Bagging(bootstrap aggregating)
bootstrap也称自助法,是一种有放回的抽样方法,目的是得到统计量的分布和置信区间。具体步骤如下:
- 采用重抽样方法(有放回)从原始样本中抽取一定数量的样本
- 根据抽出的样本计算想要得到的统计量T
- 重复上述N次(一般大于1000),得到N个统计量T
- 根据这N个统计量,计算出统计量的置信区间
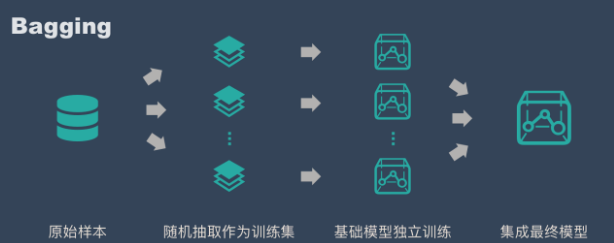
具体过程:
- 从原始样本集中抽取训练集。每轮从原始样本集中使用bootstrap的方法抽取n个训练,共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个训练集(根据具体问题采用不同的分类或回归方法,如决策树,感知器等)
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对于回归问题,计算上述模型的均值最为最后的结果。
Boosting
提升方法(Boosting)是一种可以用来减小监督学习中偏差的机器学习算法。主要也是学习一系列弱分类器,并将其组合为一个强分类器。boosting中具有代表性的是AdaBoost(Adaptive boosting)算法:刚开始训练时对每一个训练样例赋相同的权重,然后用该算法对训练集训练t轮,每次训练后,对训练失败的训练样例赋予较大的权重,也就是让学习算法在每次学习以后更注意学习错误的样本,从而得到多个预测函数。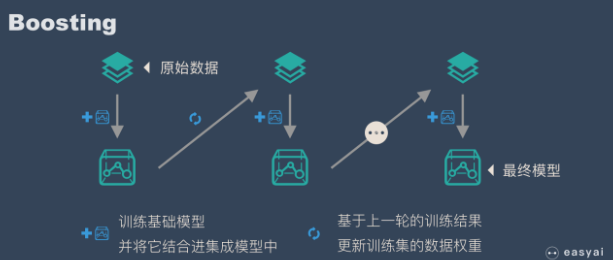
具体过程:
- 通过加法模型将基础模型进行线性组合
- 每一轮训练都提升那些错误率小的基础模型的权重,同时减小错误率高的模型权重
- 在每一轮改变训练数据的权值或概率分布,通过提高那些在前一轮被弱分类器分错样例的权值,减小分对的权值
Stacking
Stacking方法是指训练一个模型用于组合其他各个模型。首先我们先训练多个不同的模型,然后把之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。理论上,Stacking可以表示上面提到的两种Ensemble方法,只要我们采用合适的模型组合策略即可。但在实际中,我们通常使用logistic回归作为组合策略。
如下图,先在整个训练数据集上通过bootstrap抽样得到各个训练集合,得到一系列分类模型,称之为Tier 1分类器(可以采用交叉验证的方式学习),然后将输出用于训练Tier 2 分类器。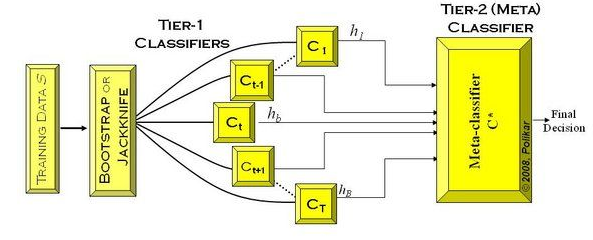
Boosting与Bagging
Bagging和Boosting采用的都是采样-学习-组合的方式,但是差别可以从四个方面概括:
- 样本选择:Bagging训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的;Boosting每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
- 样例权重:Bagging使用均匀取样,每个样例的权重相等;Boosting根据错误率不断调整样例的权值,错误率越大则权重越大
- 预测函数:Bagging所有预测函数的权重相等;Boosting每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重
- Baggign各个预测函数可以并行生成;Boosting各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果
在算法学习的时候,通常在
bias和variance之间要有一个权衡。bias与variance的关系如下图,因而模型要想达到最优的效果,必须要兼顾bias和variance,也就是要采取策略使得两者比较平衡。
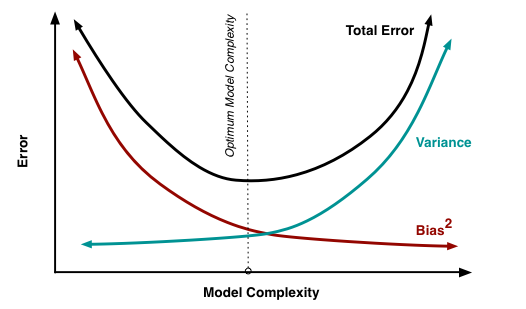
从算法来看,Bagging关注的是多个基模型的投票组合,保证了模型的稳定(variance),因而每一个基模型就要相对复杂一些以降低偏差(bias)(比如每一棵决策树都很深);而Boosting采用的策略是在每一次学习中都减少上一轮的偏差(bias),因而在保证了偏差的基础上就要将每一个基分类器简化使得方差(variance)更小。
